OpenCL的核函数(kernel function)运行效率有一个很重要的指标是核函数占用率(kernel occupancy)。这个占用百分比主要跟三个因素相关:
- Work-group size 大小
- VGPR/SGPR的个数
- LDS(Local Data Share)大小
笔者在AMD的官方文档中没有发现对于VGPR的详细介绍。这里,我们重点讲一下我对于VGPR的理解和发现的优化思路。
利用AMD APP Profilier或者CodeXL可以方便的获得对于当前硬件核函数占用率的瓶颈在哪里,如下图:
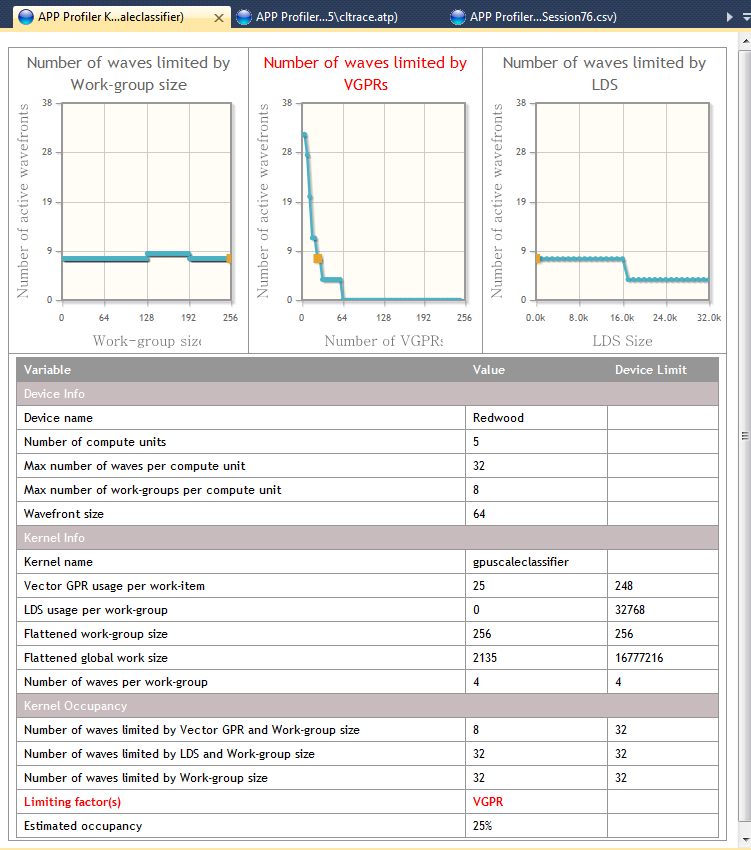
上图中我们可以看到三个曲线图。显然在这个函数中,VGPR的个数严重限制了计算单元能够同时执行的线程数。 在这个例子中,VGPR的个数有25个,导致核函数占有率只有8/32 = 25%。 如果我们能把VGPR的个数减少到20个,就能把占用率提高到12/32 = 37.5%(可把鼠标移动到图表上观察到);甚至更低 - 12个VGPR时占用率将提高到62.5%。
两条基本的原则是:
- VGPR的曲线和Work-group的大小有关系。
- Work-group的大小在1~256之间,对于AMD来说在64的倍数的时候性能是最好的。
实际优化调试过程中,用户必须根据自己的情况反复尝试改变算法的核函数实现方法,观察VGPR的个数和使用量。必要时,可能会对work-group的大小进行调节。
本文的主要测试平台为非GCN架构的Evergreen的Redwood和Northern Islands的笔记本显卡,因此没有SGPR。VGPR的个数通过AMD APP KernelAnalyer离线编译核函数得到。
我们来看一下以下三段代码片段。
###片段A###
__kernel void func1()
{
}
__kernel void func2(__global float * in)
{
}
__kernel void func3(__global float * in)
{
in[get_global_id(0)] = get_global_id(0);
}
这三段的VGPR值同为2。 第一段没有任何作用的空核函数,虽然本身没有任何指针和值存在,占用了2个VGPR。笔者猜测,其中一个VGPR是保留给了程序计数器(Program counter),另一个VGPR通过第二和第三段函数分析,是留给了一个默认的参数指针。可以认为,VGPR的个数是跟输入输出的指针个数正相关。
再看下面一段代码: ###片段B###
__kernel void func4(
__global float * in1,
__global float * in2,
__global char * in3)
{
in1[get_global_id(0)] = get_global_id(0);
in2[get_global_id(0)] = get_global_id(0);
in3[get_global_id(0)] = get_global_id(0);
}
__kernel void func5(
__global float * in1,
__global float * in2,
__global int * in3)
{
in1[get_global_id(0)] = get_global_id(0);
in2[get_global_id(0)] = get_global_id(0);
in3[get_global_id(0)] = get_global_id(0);
}
func4和func5的差别只存在于in3的类型。看似类似的写法,却可能产生巨大的性能差异,如下图:
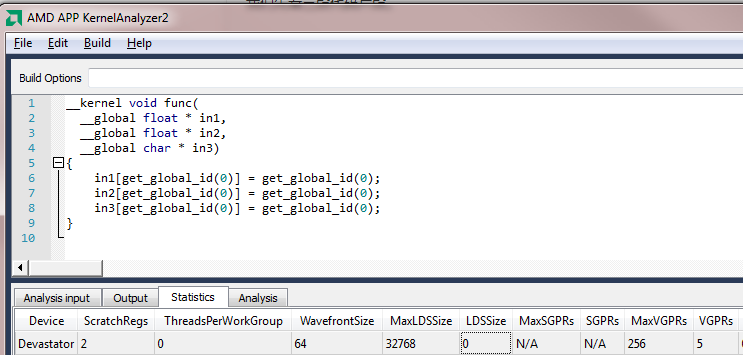
在Devastator上面,func4占用5个VGPR,而func5占用4个;
但更为严重的是,func4有非常致命的register spilling的缺陷(参见ScratchReg数目,上图为2),而func5没有这个缺陷。这个缺陷会导致核函数运行时间急剧增加。
笔者并不清楚为何会导致这样简单的程序出现Register Spilling问题。
如果你的核函数出现了类似的问题,请参考暂时把非32位倍数的数据指针替换为32位指针。比如上面的情况,把func4替换为func5,再写一个in3类型转化的核函数,在进入func5之前把in3转化为int类型,func5结束后再转化回func4。笔者实践中,这样做虽然多了2次转化,性能依然会比有Spilling Register的时候得到成倍的提高。
###片段C###
__kernel void func6(
__global int * in1,
__global int * in2
)
{
const int gid = get_global_id(0);
if(in1[gid] > in2[gid])
{
in1[gid] = gid;
}
else
{
in2[gid] = gid;
}
}
__kernel void func7(
__global int * in1,
__global int * in2
)
{
const int gid = get_global_id(0);
const bool isGreater = in1[gid] > in2[gid];
in1[gid] = isGreater ? gid : in1[gid];
in2[gid] = isGreater ? in2[gid] : gid;
}
func6和func7功能相同,不过func7并没有用到if语句。
大部分的OpenCL开发者都知道if语句会消耗很多的计算循环数。
另外,Redwood架构的分析结果显示,func6和func7占用的VGPR个数分别为5和4,就是说用到if的语句甚至会用到更多的寄存器个数。
因此在可能的情况下,请尽量避免使用if语句(或是嵌套的if语句)来对变量赋值。
##To be continued##
大概。。。写了篇漏洞百出的优化心得,心慌不安啊!