参加OpenCV的OpenCL模块(以下称OCL)移植工作已经有2个月了。这里我说移植而不是开发,是因为大部分OCL模块的函数是从已经很成熟的GPU模块直接移植过来的。因此,目前阶段OCL模块所支持的函数接口是GPU模块的一个子集,但由于运行平台差别问题,在某些函数上有些细微不同。
OpenCV的版本控制系统已经转移到了git上面(见OpenCV on GitHub),而最新的trunk的master分支也正式加入了OCL模块。今天逛OpenCV的开发者社区时,我发现有人提问在OpenCV库中如何进行使用OCL模块的函数;回答问题的同时,考虑到网上还没有针对OpenCV的OCL模块的资料,我决定写一篇文章简单介绍下OCL模块以方便开发者使用。
Introduction to OpenCL
对于OpenCL已经有所了解的,可以直接跳过这一节。
“OpenCL是用于编写在异构平台上运行程序的框架,所谓异构平台,一般情况我们指GPU和CPU两种处理器混合的平台。OpenCL由一门用于编写kernels (在OpenCL设备上运行的函数)的语言(基于C99)和一组用于定义并控制平台的API组成。” OpenCL可以实现GPGPU(General-purpose computing on graphics processing units, 通用图形处理器)运算, “(GPGPU)是一种利用处理图形任务的GPU来计算原本由CPU处理的通用计算任务。这些通用计算常常与图形处理没有任何关系。由于现代图形处理器强大的并行处理能力和可编程流水线,令流处理器可以处理非图形数据。特别在面对单指令流多数据流(SIMD),且数据处理的运算量远大于数据调度和传输的需要时,通用图形处理器在性能上大大超越了传统的中央处理器应用程序。” 摘自wikipedia
简单解释一下这段话中几个重点:
利用GPU强大的并行能力代替CPU进行运算
由于GPU本身特殊的硬件架构,GPU被设计成拥有非常强大的并行运算能力。以OpenCV为例,把GPGPU融入到OpenCV的首要原因是GPU的并行能力特别适合于关于矩阵的运算。利用GPU,我们可以发起很多个轻量级线程,每个线程仅处理一个元素的计算来实现数据并行;而对于CPU,我们只能按顺序每个元素迭代运算。GPU和CPU运算对比起来可以想象成4辆坦克与1万个士兵的战斗力水平的对比;孰胜孰劣,还要看具体进行的任务。因此,并不是所有的OpenCV函数都适合移植到GPU上进行运算;这就是为什么只有一部分的函数被移植到了GPU上运算。
OpenCL由在OpenCL设备上运行的kernel函数语言和控制平台的API组成
OpenCL包含两个主要部分:device和host。在CPU和GPU组成的异构平台中,我们一般把运行核函数的GPU处理器部分称为device,把控制平台API的CPU称为host。相应的,把host上的内存(就是内存)称为host memory;而把device上的内存(例如GPU显存)称为device memory或者device buffer。在OpenCV里,我们把这两种内存封装为cv::Mat和cv::ocl::oclMat结构。
数据调度和传输
OpenCV的OCL模块中,在GPU上进行运算之前我们必须把内存转成GPU可以直接调用的显存。而在GPU上的运算结束后,我们还需要将在GPU显存上的数据转移到CPU可用的内存上。这两个操作在oclMat中定义为两个成员函数,分别为oclMat::download和oclMat::upload。由于这两个数据传输操作受PCI总线宽带的限制,在实际应用中应尽量减少数据传输,把尽可能多的运算在gpu device上计算完成后,再把数据传回cpu host,以达到最大的数据吞吐量。
我们正在考虑在未来版本中加入对于通过设备内存映射,直接让设备读取主机内存的方式。这种方法可能对于AMD APU或者Intel Sandy Bridge集显来说有先天优势。
OpenCV’s CUDA Module
介绍OpenCL模块前,不得不先提一下OpenCV的GPU(以下特指CUDA模块)模块。由于OCL模块有很大一部分直接移植自GPU的代码,所以我们可以先来了解下他的前身。
来源:http://opencv.org/platforms/cuda.html
历史
GPU模块最初由NVIDIA公司在2010年起支持开发,2011年春发布了第一个带有GPU模块的OpenCV版本。GPU模块包含并加速了很大一部分原先只能运行在CPU设备上的库函数,并且随着新的计算技术和GPU架构不断发展和更新。
目标
- 为开发者提供一个便于使用CUDA的计算机视觉框架,同时在概念上保持了当前的CPU的功能性。
- 把用最高效的方式优化GPU模块函数作为目标。这些优化方法包含:适应最新的硬件架构;非同步模式核函数执行;重叠式拷贝和零拷贝等。
- 功能完整性。意思就是说即使有些函数性能并没有提高的情况下,尽可能的把CPU模块函数移植到GPU上去做,以减少数据传输产生的延迟。
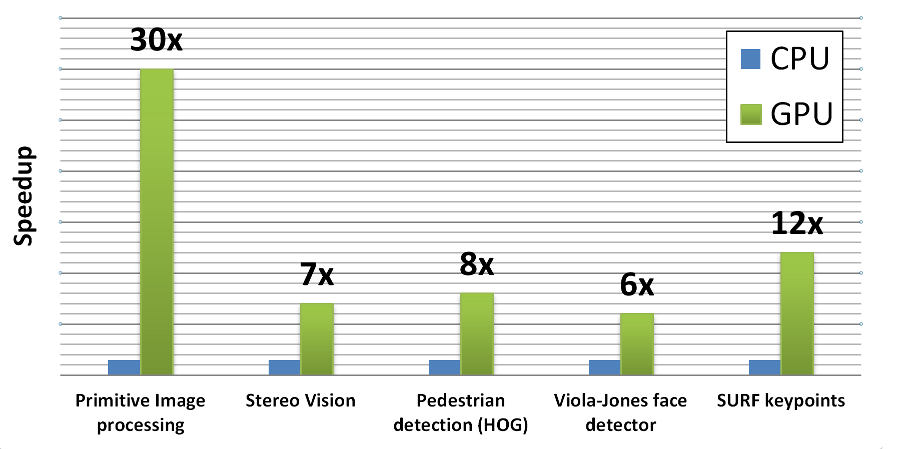
模块设计
OpenCV的GPU模块还加入了CUDA第三方函数的支持,如NVIDIA NPP和CUFFT。(相应的,OCL模块也加入了AMD提供的amdBlas和amdFft库)
GPU模块被设计成host上能调用的CUDA API扩展集。这个设计模式让开发者能明确的控制数据在CPU和GPU的内存间的传输。尽管用户必须要多写一点代码来开始使用GPU模块,但是这个过程是灵活的,并且允许用户对GPU数据控制的代码进行优化。
GPU模块的gpu::GpuMat类是一个封装了储存在在GPU显存的容器,而他的接口与CPU的cv::Mat类非常相似。所有的GPU模块函数以GpuMat作为输入输出函数,这样的设计允许多个GPU算法在数据不下载到CPU内存就能完全调用,增加了数据吞吐效率。并且GPU函数接口也尽可能的和CPU函数保持移植,这样熟悉OpenCV CPU操作的开发者能直接转移到GPU模块上进行开发。
由于OpenCL的开发模式与CUDA非常类似,包括host API和device上运行的核函数语法,所以移植工作并不困难。移植过程中,我们保持了GPU模块的设计理念,并且在保证代码质量的基础上,尽可能的让OCL模块的函数跟上GPU模块的更新节奏。
Compile Latest OpenCV trunk repository
以下以windows 7 32bit + visual studio 2010 + AMD显卡为例。
由于ocl模块刚刚加入OpenCV的主版本,用户想要基于ocl开发的话,需要从OpenCV的git服务器上pull一下最新trunk repository的OpenCV代码。git地址如下:
git://code.opencv.org/opencv.git
或者github的镜像
https://github.com/itseez/opencv
下载完成后,你还需要一个新的OpenCL SDK。以AMD显卡系列为例,APP SDK v2.7下载地址http://developer.amd.com/sdks/amdappsdk/downloads/pages/default.aspx
你还需要CMake2.8版本来生成Visual Studio的sln项目。cmake的使用方法就不多说了,网上有很详细的教程。
应注意的是在用CMake对OpenCV项目进行配置时,要手动打开WITH_OPENCL选项,这个是默认关闭的。如果一切正常的话,在CMake的命令行输出终究会提示找到OpenCL的静态库和include文件夹;如果提示没有找到的话,需要自己手动在cmake中找到这两个选项(分别是OPENCL_INCLUDE_DIR和OPENCL_LIBRARY),添加include文件夹和静态库文件(OpenCL.lib)路径。
上面步骤完成后,就可以打开OpenCL.sln文件编译OpenCV了。
Using OCL module
使用ocl模块的方法跟gpu非常类似(本来就是无脑移植什么的)。
为了跟gpu模块使用方式保持一致,目前官网的版本(2.4.6)的部分函数已经可以隐式的初始化OpenCL环境了,例如ocl::Canny。调用任意OpenCV函数后,会自动寻找环境中的OpenCL设备,并把找到的第一个加入全局中。
默认情况下,将会把找到的第一个平台的第一个设备的上下文cl_context和一个命令执行队列cl_command_queue加入到全局环境中的Context()。你还可以调用ocl::setDevice()手动选择使用的OpenCL设备。
如果用户的电脑有多个OpenCL平台/设备,可以在环境变量中加入一个新的字段OPENCV_OPENCL_DEVICE,内容为<Platform>:<CPU|GPU|ACCELERATOR|nothing=GPU/CPU>:<deviceName>。比如,我想使用AMD的Tahiti显卡,就可以写AMD:GPU:Tahiti。
上文提到,所有的ocl模块调用的矩阵类型格式是oclMat。oclMat跟Mat结构类似,包含大部分的成员函数和成员变量,但是最重要的是封装了OpenCL的buffer数据(cl_mem)并控制他的内存释放与传输。
把一个Mat转化成oclMat非常简单,你可以调用oclMat的构造函数:
oclMat myOclMat(mat); // mat is a Mat object oclMat的构造函数会自动复制据Mat的矩阵头(header),如列、行数,元素类型,通道数等等,分配一个足够大小的设备储存,并且隐式的把cpu host上的内存转移到gpu device的显存上。如果用户想显示的转移(或者称为“上传”),可以调用:
oclMat myOclMat;
myOclMat.upload(mat); 这样我们就有了一个上传到device上的oclMat矩阵。这个矩阵数据就可以传递给ocl模块的函数,进行你所需要的运算。但是由于oclMat矩阵的数据是储存在gpu显存上的,我们在host(cpp文件中)是不能直接去取值的(除非利用host内存地址映射)。如果计算完毕后,我们想取得oclMat的结果,需要把在显存上的oclMat数据转移成Mat格式,这个操作叫做”下载”。跟上传类似,我们也有隐式和显示两种方法:
mat = (Mat)myOclMat;
myOclMat.download(mat); 一般情况下,你不必担心oclMat数据的释放问题,因为跟Mat相同,它是有reference count控制显存的释放。有些情况下GPU显存十分紧张的时候,就需要用户自己去释放oclMat,或者考虑显存的重复利用。
概括地说,使用ocl模块有这么几个过程:
- 注册全局OpenCL设备。 //此步可以省去,新版本的OpenCV会自动注册OpenCL设备
- 把内存的数据上传到显存。//把
Mat转化成oclMat - 在OpenCL设备上进行计算。//调用
ocl模块函数 - 把显存的数据下载到内存。//把
oclMat转化成Mat - 在host上进行剩余的运算。//调用
cv::函数
Info 虽然开发者已经尽量通过函数的封装减少了用户对于实际函数调用流程的透明度,但是用户使用模块前应了解以下几点:
- 尽量减少在OpenCL函数调用之间加入数据传输指令。这是因为上传下载操作会严重影响核函数在命令队列上的调度,尤其是下载操作,因为这个操作在库中被设计成同步指令。
有的函数有隐式的下载调用,比如
cv::ocl::sum,应尽量调整其执行的顺序,必要的时候使用AMD CodeXL看一下命令队列的执行密度。 - 用户使用过程中会注意到,目前的OCL模块编译速度要比CUDA(GPU)模块快的多,后者可能要编译一小时以上。 但是运行时,OCL模块的函数在第一次调用的时候会有很明显的延迟,但CUDA模块没有这种现象。 这是因为CUDA模块在OpenCV编译其会把核函数编译为cubin文件,这样在运行时就不会出现启动延迟,但是为了兼容不同的CUDA版本和CUDA文件的高度模版化,导致编译时间相当漫长;相比较OpenCL,我们不能在OCL函数运行之前就确定核函数的编译选项和目标运行平台,因此只能在运行时进行核函数的编译。 作为一个补救措施,我们加入了一个功能,OCL模块在第一次运行时将把这一次编译好的核函数二进制文件保存到磁盘,这样下一次使用的时候就避免了编译造成的启动延迟。
以下是OCL模块的例子SURF matcher的输出结果示例:

PS
下载到的OpenCV的trunk代码中包含了几个OpenCL的sample程序可以作为开发者的参考。
谢谢阅读~
鹏
August 19, 2012