##Intro
对于简单OpenCL程序来说,开发者只要知道大概的OpenCL C的语法和Runtime API调用,
把for循环替换成kernel线程,就能使用OpenCL获得明显的加速比。
例如,矩阵的加减法运算,模版匹配算法等。这从另一方面体现出了OpenCL的强大之处:
我们不需要详细了解运行目标设备的参数和架构,就能用统一的方法跨平台,多、超线程编程,实现算法的加速。
不过对于有些复杂的算法,我们发现即使为它分配了大量线程,做到了高度的并发, 但由于内核程序撰写质量的问题,导致GPU占用率并不高,或者内存访问方式缺陷,使得性能离预期的加速比相差甚远,很可能是由于CPU设备上的程序(C++)写法并不适合GPU架构; 另一方面,有时候我们要为特殊的OpenCL设备进行优化,例如移动平台、AMD HD79xx系列的GCN架构等,就得充分利用目标设备的特性。
笔者的OpenCL知识主要来源于AMD APP Programming Guide [1],目标硬件设备是AMD的独立显卡。 跟大部分的OpenCL教程不同,它从开始就简明的分析AMD硬件的架构, 让读者去了解OpenCL的线程是如何分配到各个GPU的核心上去的,来挖掘显卡设备潜在的强大性能。 不过由于笔者知识储备的不足,在OpenCL学习之初并没有充分理解这一部分 的内容。更惭愧的是,经过了1年的OpenCL相关工作实践,笔者并没有加深AMD显卡架构的理解, 尤其是在OpenCL核函数优化方面步履维艰。
于是乎,就有了这一篇 入门 级别的笔记博文。同时感谢让我感受到自己不足的南千秋(原名不详)老师。
##AMD显卡Compute Unit架构 AMD的GPU是由多个Comput Unit(CU,运算单元)组成的,CU的数目和架构因不同的显卡系列和型号有差别。 一个CU含有多个Processing Elements,又被称为Streaming Processor,一个work-item线程运行时将占用一个PE。
####非GCN架构,以Evergreen和Northen Islands设备为代表 我们先来了解一下出现在GCN之前的AMD传统显卡架构。 简单来讲,每一个Compute Unit都是一个SIMD(Single Instruction, Multiple Data)运算部件,共享同一个Program counter。 每一个Compute Unit含有16个Processing Element(PE)。 每个PE有自己的General-Purpose Registers(GPR)寄存器; 根据设备不同,可能含有3到4个负责向量运算的ALU,一个标量运算的ALU和一个分支执行单元。
不同的CU之间是独立运行的;但是对于同一个CU里的PE所执行的每个work-item,则是按SIMD的模式执行。
如Figure 1:

在GCN设备之前,PE执行的指令被称为Very Long Instruction Word(VLIW), 根据PE所含ALU(Arithmetic logic unit)的个数不同,有VLIW4和VLW5的区别, PE中的4或5个ALU将协作完成一个VLIW指令。
借助于编译器优化,编译器会把2~5个没有依赖性的指令操作合成1个的VLIW指令。 对于常见的计算机图形处理,操作的数据一般是RGBA各个颜色通道分别计算, VLIW这样的设计能提高ALU的占用率,减少GPU核心的时钟周期次数,从而提高GPU的运算效率, 开发人员也可以借助向量化 Vectorization 手动实现这个操作。 另一方面,最差情况下,1个VLIW指令只含有1条原始指令,导致剩下的ALU会闲置,将会大大减少GPU的运算效率。
一段核函数程序将被编译成一串连续的VLIW指令,分配到Wavefront的规划在编译期间就是确定的了。 核函数运行时,CU会依次从指令队列中读取VLIW指令。用户设定的总线程数被驱动以64个线程一组划分(称作一个Wavefront)来执行,分布到各个CU上。每个CU的16个PE组会同时执行同样的VLIW指令,循环4次,组成一个Wavefront。 如下图,临近的颜色相同的方块表示可以向量化的指令:
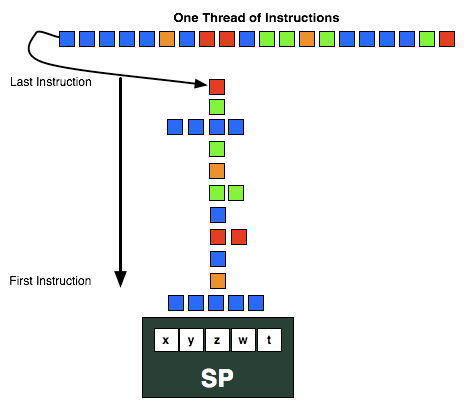
但是,普遍意义上的运算中由于数据依赖性通常要比图形像素操作高的多,因此很多情况下并不能做到向量化操作,使得PE的使用不够充分。 并且,由于VLIW指令都是在编译期确定的,函数运行中并不能动态的规划指令的分发, 就算是非常优秀的编译器,依然会产生运算效率不高的情况。 例如,由于线程是严格的按照64个线程来执行的,如果运行时同一个Wavefront的某1个线程进入了不同的分支,将会导致剩下的63个work-item线程闲置,直到这个线程分支结束;另一方面,由于VLIW指令的复杂度令优化、分析瓶颈和预估性能也产生了困难。
以AMD Radeon HD5870为例:20个CU,每个CU有16个PE,每个PE有5个ALU(1个标量, 4个向量),总计1600个ALU。 就是说,这个设备能同时支持20个wavefront的并发,因此同时并发的work-item线程数为20 * 64 = 1280。
####GCN架构,以Southern Islands设备为代表 Graphics Cores Next,GCN [2] 架构是AMD专门为通用计算设计的显卡架构,始于AMD HD79xx系列显卡,以 HD7970显卡为代表。

与Northern Islands架构不同,GCN架构的一个CU含有4个SIMD。每个SIMD更接近CPU的SIMD架构,
如下图,每个SIMD含有16个向量ALU(或称为PE)和一个64KB的缓存区域(包含寄存器,外加10个Wavefront的指令缓存)。

这种架构使得每个CU能同时执行4条不同的指令。一个Wavefront中,指令在每个SIMD的16个PE执行4次循环(4个时钟周期)。通过这种方式,依然使得Wavefront的大小限制在了64。 每个SIMD有一个专门用来储存10个Wavefront指令的缓存,这样一个CU所能缓存的Wavefront个数达到了40个; 同时,这些指令的提取是通过硬件(而不是编译器编译期间确定的), 使得GPU硬件的控制设备能规划Wavefront的分发,SIMD根据优先级从10个Wavefront中选择要去执行的指令。
由于GCN架构CU中SIMD的Wavefront缓存机制,使得GCN架构同时并发的work-item线程数大大增加。
如AMD Radeon™ HD 7970,有32个CU,每个CU能同时并发40个Wavefront,使得同能最大能并发的线程数达到了32 * 40 * 64 = 81920个work item。
对比来看VLIW4 SIMD和GCN SIMD,每4个时钟周期,非GCN架构执行1条VLIW4指令,一个VLIW4指令最多执行4个ALU操作指令, 受数据依赖性限制;而GCN架构的SIMD每4个时钟周期只执行1个ALU操作指令,但是每个CU的4个SIMD可以执行不同的指令,使得GPU性能主要受占用率影响。后面我们将会提到,GCN的架构使得向量化成为不必要的操作。
VLIW的问题在于Wavefront的线程可能有依赖性存在导致的GPU性能利用率降低;GCN架构中,每个SIMD有一个可以储存10 个Wavefront信息的buffer,并且由于指令依赖性的分离(例如barrier同步指令),SIMD可以在一条指令结束后,跳到不同的Wavefront来进行工作,增加GPU设备的利用率。
另一方面,由于指令的简化,编译器的优化也变得十分简单,而且更容易做性能优化。 为VLIW由于架构的优化可能并不适合GCN架构,例如向量化Vectorization 并不能在GCN架构上获得任何性能提高,反而可能会由于指令的依赖性导致GPU不能更大程度的动态调整指令的分配。
GCN与非GCN架构不同之处还在于每一个CU加入了一个单独的标量ALU。 这个特殊的ALU可以用来加速处理特殊的条件分支指令和跳转指令: 由于这个ALU每个指令只执行一次循环,可以减少对于SIMD(需要4次循环)的运算开销。
##Further thoughts 说了这么多,好像跟OpenCL没什么关系 - -! 而更复杂的内容,比如L1、L2缓存,LDS和GDS,xp羞于自身水平,并不能准确的给出什么有用的信息。 等xp有了更多的感悟后,可能会回来重新修订这篇文章。
####To be continued …大概…
##参考资料 [1] AMD APP Programming Guide
[2] AMD GRAPHICS CORES NEXT (GCN) ARCHITECTURE
[3] AMD’s Graphics Core Next Preview: AMD’s New GPU, Architected For Compute